RAG (Retrieval-Augmented Generation,检索增强生成) 是一种将强大的信息检索 (Information Retrieval, IR) 技术与生成式大语言模型 (LLM) 相结合的框架。检索指的是检索外部知识库,增强生成指的是将检索到的知识送给大语言模型以此来优化大模型的生成结果,使得大模型在生成更精确、更贴合上下文答案的同时,也能有效减少产生误导性信息的可能。
💡 一句话总结:RAG 就是让 LLM 学会了”开卷考试”,它既能利用自己学到的知识,也能随时查阅外部资料,主要也是为了解决存在的一些局限性。
RAG 概念最早是 2020 年 Meta(当时还叫 Facebook AI)的研究团队提出的。他们的思路很直接:与其让模型把所有东西都记在脑子里,不如教它”先查资料,再回答”。这样一来,模型的回答就有据可依了——既利用了大模型理解语义的能力,又能接入最新的、私有的知识库数据。
RAG 过程:索引和检索
RAG 过程分为两个不同阶段:索引和检索。
在索引阶段,文档会进行预处理,以便在检索阶段实现高效搜索。该阶段通常包括以下步骤:
- 输入文档:文档是需要被处理的内容来源,可能是文本文件、PDF、网页、数据库记录等。
- 清理文档:对文档进行去噪处理,移除无用内容(如 HTML 标签、特殊字符)。
- 增强文档:利用附加数据和元数据(如时间戳、分类标签)为文档片段提供更多上下文信息。
- 文档拆分(Chunking):通过文本分割器将文档拆分为较小的文本片段,严格适配嵌入模型和生成模型的上下文窗口限制。
- 向量化表示 (Embedding):通过嵌入模型将文本片段映射为语义向量表示(Document Embedding,也就是高维稠密向量)。
- 存储到向量数据库:将生成的嵌入向量、原始内容及其对应的元数据存入向量存储库(如 Milvus, Faiss 或 pgvector)。
索引过程通常是离线完成的,例如通过定时任务进行重新索引。对于动态需求,例如用户上传文档的场景,索引可以在线完成,并集成到主应用程序中。

RAG 最适合的使用场景
RAG(检索增强生成)最适合用在 “答案依赖外部资料、且资料会变化/很长” 的场景:先从知识库检索相关内容,再让大模型基于检索结果生成回答,从而减少胡编、提升可追溯性。
下面列举几个最常见的场景:
- 智能客服:传统客服机器人靠的是关键词匹配和预设问答对,覆盖不到的问题就抓瞎。接入 RAG 后,可以把产品文档、FAQ、历史工单都灌进去,回答的范围和灵活度都上了一个台阶。
- 智能研发/运维助手:检索代码库、接口文档、告警手册,辅助定位问题与生成修复建议。
- 医疗助手:检索指南/药品说明/院内规范后生成辅助建议(不做最终诊断)。
- 法律咨询:基于法规条文/案例/合同模板检索,生成条款解释与风险提示。
- 教育辅导:从教材/讲义/题库检索知识点,生成讲解与例题步骤。
- 企业内部知识库:员工想查公司的报销制度、请假流程、技术规范,以前要么翻 Wiki 翻半天,要么直接问同事。
- 其他:投研/合规/审计;销售/方案支持。
RAG 技术演进
RAG 的技术架构经历了从简单到复杂的演进,大致可分为三个阶段:
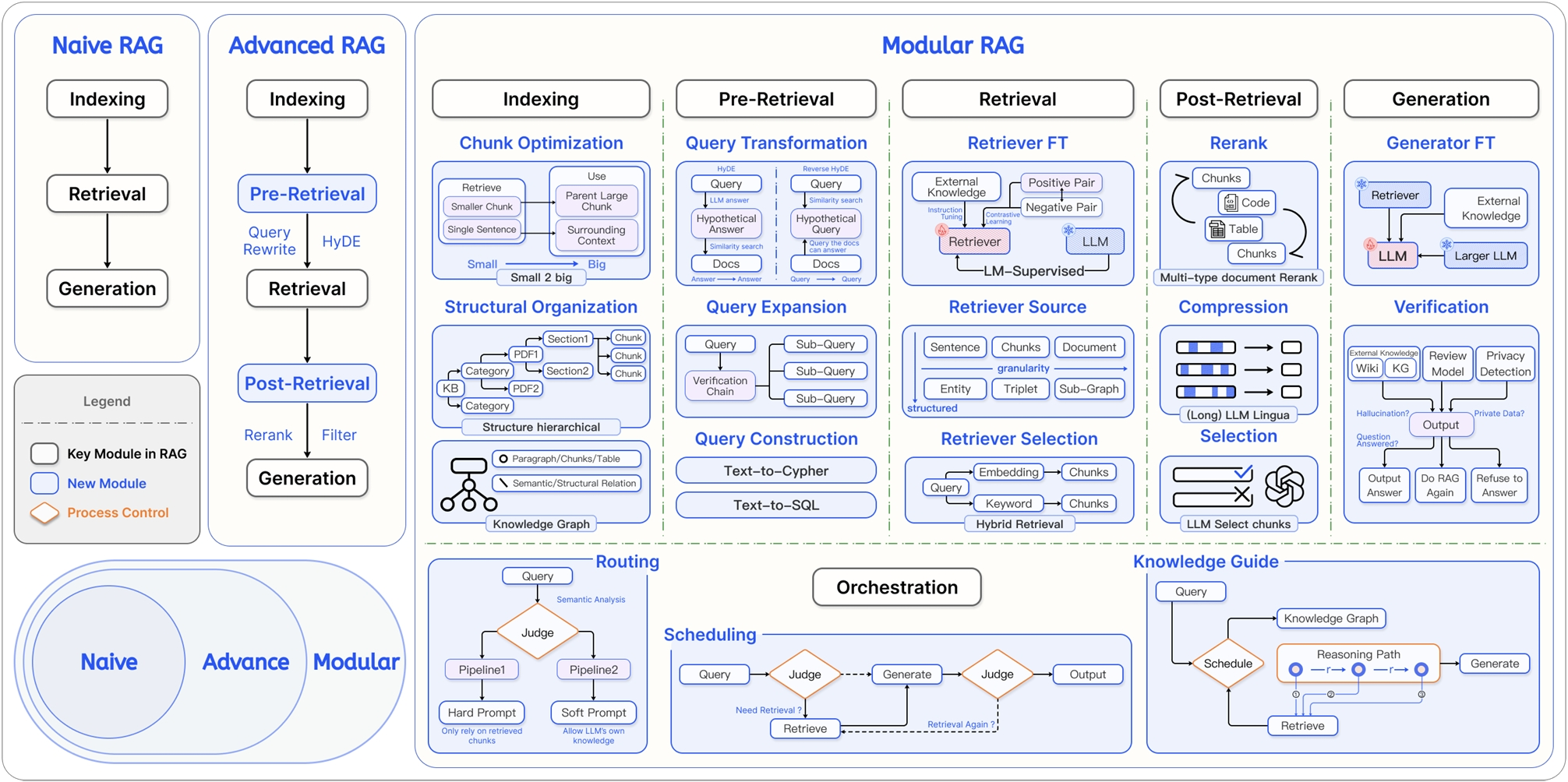
这三个阶段的具体对比如下表:
| 初级 RAG(Naive RAG) | 高级 RAG(Advanced RAG) | 模块化 RAG(Modular RAG) | |
|---|---|---|---|
| 流程 | 离线: 索引 在线: 检索 → 生成 | 离线: 索引 在线: …→ 检索前 → … → 检索后 → … | 积木式可编排流程 |
| 特点 | 基础线性流程 | 增加检索前后的优化步骤 | 模块化、可组合、可动态调整 |
| 关键技术 | 基础向量检索 | 查询重写(Query Rewrite)、结果重排(Rerank) | 动态路由、查询转换、多路融合 |
| 局限性 | 效果不稳定,难以优化 | 流程相对固定,优化点有限 | 系统复杂性高 |
“离线”指提前完成的数据预处理工作(如索引构建);”在线”指用户发起请求后的实时处理流程。
RAG 的核心优势和局限性
RAG 的核心优势和局限性可以从知识管理、工程落地和性能指标三个维度来分析:
核心优势
- 知识时效性与低维护成本:相比微调,RAG 无需重新训练模型。只需更新向量数据库或知识库,模型就能立即获取最新信息,非常适合处理新闻、法规、产品文档等频繁变动的数据。
- 显著降低幻觉并提供引文追溯:RAG 将模型从”基于参数化记忆生成”转变为”基于检索证据生成”。每个回答都有明确的信息来源,提供了关键的可解释性和可验证性。
- 数据安全与细粒度权限控制:可以在检索层实现精准的多租户隔离和访问控制(ACL),确保用户只能检索其权限范围内的数据。
- 领域适应性强:无需针对特定领域重新训练模型,只需构建领域知识库即可快速适配垂直场景。
局限性与工程挑战
- 严重的检索依赖性:遵循 GIGO(Garbage In, Garbage Out)原则。如果输入的信息质量不好,即便下游模型再强,也很难输出正确的结果。
- 上下文窗口与推理噪声:注入过多无关片段会造成注意力稀释,干扰模型的逻辑推理,且带来不必要的 Token 开销。
- 首字延迟(TTFT)增加:完整链路包括”查询改写 -> 向量化 -> 相似度检索 -> 重排序 -> 上下文构建 -> LLM 生成”,每个环节都增加延迟。
- 工程复杂度:需要维护向量数据库、处理文档更新的增量索引、优化检索策略等,相比纯 LLM 应用复杂度大幅提升。
- 长文本 Token 成本:单次请求携带大量上下文会导致推理成本显著高于普通对话。