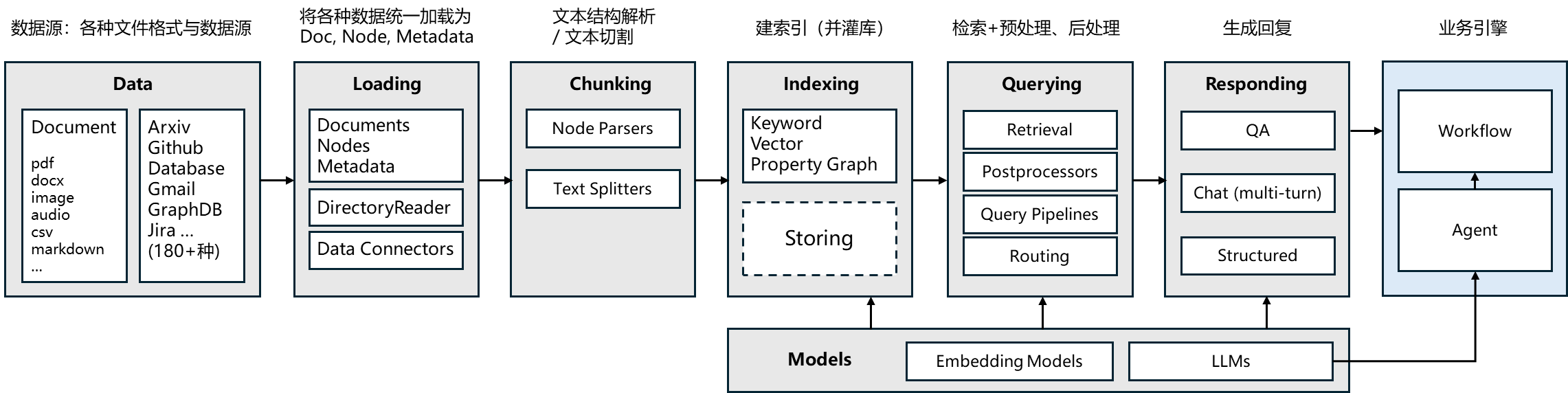
搭 RAG 系统这件事,链路其实不复杂:加载文档 → 切块 → 向量化 → 存向量库 → 检索 → 组装 Prompt → 调 LLM 生成。
听起来没几件事对吧?但自己做的话,每个环节都要自己写代码拼接:PDF 解析器怎么接,向量数据库怎么连,Embedding 模型怎么调参,Prompt 模板怎么设计……光这些就能消耗掉你好几天。
LlamaIndex 解决的就是这个问题——它把 RAG 链路上的各个环节封装好了,你不需要从零拼积木,直接调用它的高级接口,最快半天就能跑通一个能用的 RAG 系统。
LlamaIndex 是什么
LlamaIndex 是一个专门为 LLM 设计的数据连接和检索框架。说人话就是:它帮你把各种格式的文档(PDF、Word、网页、数据库)读进来,帮你切成块,帮你转成向量,帮你存好,然后在你提问的时候帮你找出最相关的内容,一起塞进 Prompt 里让 LLM 来回答。
它做的事情,本质上就是在 LLM 和你的私有数据之间搭一座桥。
我第一次用它的时候,印象最深的一点是开箱即用。你不需要懂向量数据库的底层原理,不需要自己写相似度搜索,几行代码就能搭出一个能跑的系统。Python 生态里它基本是 RAG 这件事的事实标准,社区活跃,文档完善,遇到问题好查资料。
当然它不是万能的。LlamaIndex 擅长的是数据索引和检索这一块,如果你要做复杂的 Agent 工作流编排,LangChain 可能更合适。两者不是替代关系,经常结合着用——LlamaIndex 负责检索,LangChain 负责编排。但如果你就是想快速搭一个 RAG 原型出来,LlamaIndex 是最好的起点。
核心功能
说几个我实际用下来觉得最实在的功能。
多格式文档加载。 PDF、Word、TXT、HTML、Markdown,这些常见的格式直接读,不用自己处理解析逻辑。网页也行,扔一个 URL 进去它能自己抓。数据库、API、Notion、Slack,也都有现成的接口。基本上你日常会遇到的数据源,它都封装好了。
多种索引结构。 不只是向量索引,还支持树状索引、关键词表,知识图谱索引。不同的索引结构适合不同的查询场景,比如树状索引适合做摘要和总结,向量索引适合做语义检索。选哪个取决于你的实际需求,没有绝对的好坏。
灵活的检索和查询引擎。 向量相似度搜索、混合检索(向量加关键词一起搜)、子问题分解(把复杂问题拆成几个子问题分别检索再合并),这些都有现成的实现。你不需要自己写 Rerank,不需要自己写查询改写,调几个参数就能用。
跟主流 LLM 和 Embedding 模型都可以接。 OpenAI、Claude、Llama、本地模型、国内的通义千问、智谱,都支持。Embedding 模型也是,OpenAI 的、 Hugging Face 开源的、本地部署的,都可以。换模型改个配置就行,不用动业务逻辑。
快速上手
说再多不如直接动手。这部分我带你来搭一个最基础的 RAG 系统,Python 加 LlamaIndex 加阿里百炼的 API,半小时能跑起来。
第一步,准备环境。
你需要 Python 3.10 以上,没有的话去 python.org 下载安装。装好之后,新建一个目录,创建虚拟环境:
1 | python -m venv .venv |
然后装依赖:
1 | pip install llama-index-core llama-index-embeddings-dashscope llama-index-llms-dashscope |
阿里百炼的 API Key 去这个地址申请:https://bailian.conloud.com/cn-beijing,注册就送一定的免费额度,够学习用了。
第二步,配置 API Key。
此处使用 minimax(付费大模型)+ 阿里百炼(用量收费-embedding)进行示例。minimax 的 key 地址:https://platform.minimaxi.com/user-center/payment/token-plan;阿里百炼的 key 地址:https://bailian.console.aliyun.com/cn-beijing?tab=demohouse#/api-key
第三步,准备你的知识库文档。
我在本地放了一个中国近代史.txt,里面是一段关于中国近代史的文字。你也可以换成 PDF、Word,随便什么格式,LlamaIndex 都能读。
第四步,写代码。
代码地址:https://github.com/tyronczt/ai-learn/blob/main/rag/src/test/main.py
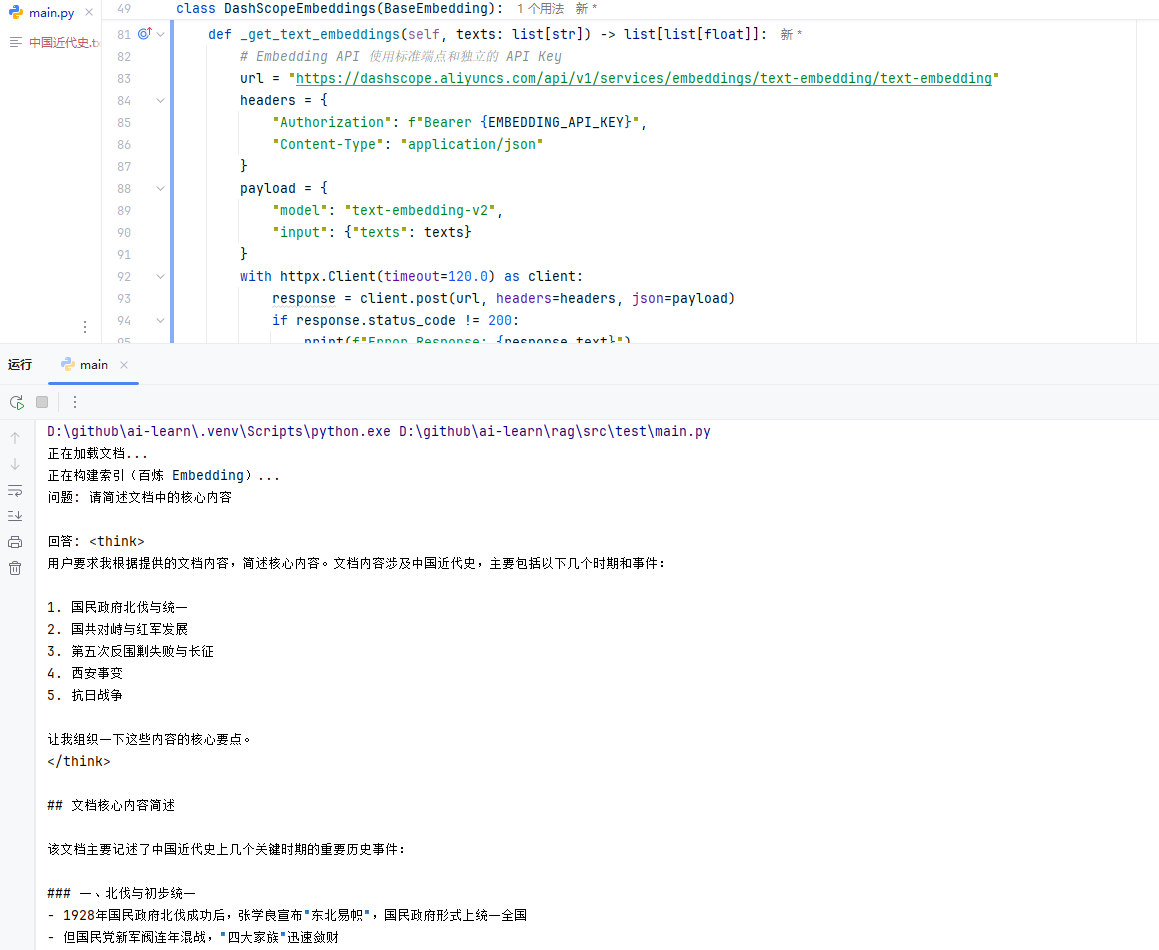
文档扔进去,问题扔进去,答案出来了。整个 RAG 链路你从头到尾走了一遍,每个环节在代码里都能找到对应的东西——这就是我说的”先跑通全链路”的意思。
效果评估
搭完了,接下来你得知道它到底行不行。
最土但最有效的方法:列一批高频问题,自己手动问一遍,记录答案质量。
这听起来很笨,但真的管用。你能立刻发现系统在哪些问题上答得好、哪些问题上答得差。答得差的问题是什么原因——是检索没召回正确内容,还是召回了但模型没理解,还是根本没这个问题在知识库里。
进阶一点的做法是用 RAGAS 这类评测框架,自动化地跑问答集、计算指标。但我建议先把这个土办法跑通,建立起手感,再上自动化工具。
总结
LlamaIndex 是一个很好的 RAG 入门工具,它让你可以在最短的时间内把整个 RAG 链路跑通,建立起对这件事的直观感受。
但它只是一个起点。
真正的工程挑战在后面:文档解析怎么处理分页和表格,向量数据库怎么选怎么部署,检索策略怎么跟业务场景匹配,线上服务的延迟和成本怎么控制——这些问题 LlamaIndex 本身解决不了,需要你自己去设计、去踩坑。
好消息是,你现在已经知道 RAG 链路长什么样了,后面的事情,都是在这个基础上加细节。
下一节我们来聊一个经常被忽视但极其重要的环节:数据加载——文档怎么解析、怎么清洗、怎么为分块和向量化做好准备。